
The AI CapEx Cliff
Why the life of GenAI hardware will shatter tech margins - and how to position for the impending wave of write-downs.
The hyperscalers - entities which historically possessed zero marginal distribution costs, infinite operating leverage, and historically asset-light balance sheets - are currently executing the most massive, speculative CapEx cycle in the history of corporate finance.
In 2026 alone, the top five US hyperscalers - Microsoft, Alphabet, Amazon, Meta, and Oracle - are projected to spend $602-$690 billion in pure CapEx. This is a 36% YoY increase from their already unprecedented 2025 levels, driving capital intensity to historically unthinkable levels of 45% to 57% of total revenue.
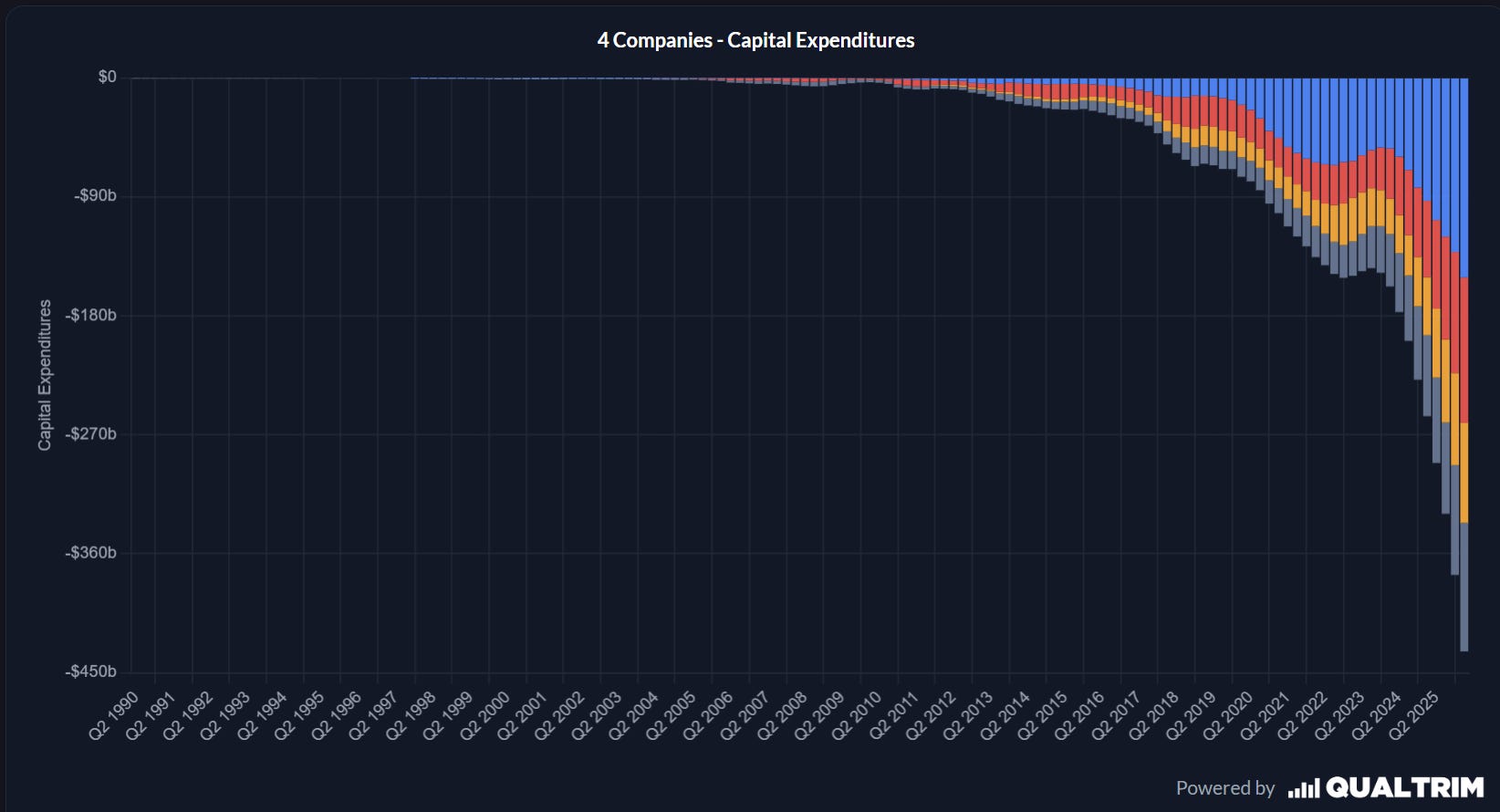
To put this staggering allocation of capital into its proper macroeconomic perspective, this single-year expenditure vastly exceeds the combined military spending of Germany, France, the UK, Japan, Italy, and Canada, and roughly equates to the entire GDP of Sweden.
Over a broader timeline, baseline aggregate AI CapEx estimates point to an unfathomable $7.6 trillion of capital deployment required between 2026 and 2031 across compute, data centres, and power delivery.
This is no longer a software industry. It is a heavy industrial manufacturing build-out which tech CEOs want to call a mere cloud transition.
However, the true peril lies not merely in the absolute amount of capital deployed, but in the aggressive financial mechanisms utilised to mask the rapid physical decay of these underlying assets. The current market narrative, heavily sponsored by the hyperscalers themselves and digested unquestioningly by tech analysts, assumes this newly acquired GenAI hardware possesses a standard 4-6 year useful life, smoothly amortising on the balance sheet while reliably generating high-margin cash flows into the next decade.

This assumption is an error. GenAI hardware does not age like traditional cloud computing hardware; it faces rapid obsolescence. The financial ecosystem is currently marching blindly towards a cliff edge, entirely oblivious to an impending financial and engineering trap.
This article will discuss the specifics of that exact trap. The hundreds of billions of dollars currently sitting on big tech balance sheets are not durable, long-term assets generating perpetual utility. They are rapidly decaying silicon, soon to become essentially scrap.
The hyperscalers are locked in a zero-sum, hyper-competitive arms race where they are forced to continuously destroy their own capital just to avoid losing market share to their peers, spending exponentially greater amounts on assets that possess the economic half-life of a fruit fly.
The Cloud vs AI
The market is inappropriately, mapping the depreciation of the 2012–2022 cloud computing decade directly onto the AI decade. While it may be a shock to many, the two paradigms share almost no physical or economic similarities.
Commodity Compute vs Frontier Training
In the traditional cloud era, a CPU server purchased by AWS or Azure degraded incredibly slowly in terms of its pure economic utility. A five-year-old Intel Xeon server could be easily and profitably repurposed to run basic enterprise database queries, host legacy web applications, manage standard microservices, or execute routine back-office computations perfectly fine.
The hardware commoditised, but it retained a highly resilient baseline of utility. The economic lifecycle smoothly tracked the physical lifecycle. If a server physically powered on and successfully connected to the network fabric, it could be rented out to generate a margin.
In the GenAI era, hardware performance no longer scales linearly. It now drops off an absolute cliff. The physical parameters required to train frontier models - models now possessing parameters reaching into the hundreds of trillions - demand exponential leaps in memory bandwidth, cluster-to-cluster interconnect speeds, and raw thermal density.

An Nvidia H100 cluster purchased in 2024 at peak scarcity pricing is completely unequipped to handle the synchronised data transmission requirements of the frontier models being developed in 2026. The technological leap from Nvidia’s Hopper architecture (2022) to Blackwell (2024), and subsequently to Rubin (2026) and the slated Rubin Ultra (2027), demonstrates a speed of innovation that breaks traditional infrastructure pricing models.
This obsolescence is dictated by the cost of ownership of a modern data centre. Power consumption is the dominant, inescapable operational cost in any hyperscale facility. When a newer generation of silicon, such as Blackwell, offers up to a 25-fold improvement in energy efficiency for specific inference workloads compared to its immediate Hopper predecessor, operating the older hardware becomes economically irrational within 18-36 months.
The older hardware consumes excessive, highly expensive power for vastly inferior computational output, breaching the power usage effectiveness constraints of the data centre itself. The utility drops to near-zero long before the physical asset depreciates to zero on the company’s balance sheet.
Furthermore, the physical stress placed upon these assets is fundamentally different from traditional cloud operations. Operating high-utilisation training clusters subjects the GPUs to extreme physical and thermal degradation. Meta’s Llama 3 405B training study, which used a cluster of 16,384 H100 GPUs, documented 148 severe GPU failures out of 419 total cluster disruptions over a mere 54-day period.
This extrapolates to an annualised failure rate of ~9% - a staggering level of physical degradation that is entirely incompatible with the extended operational lifespans currently assumed by accounting departments.
The Collapse of the GPU Value Cascade
To defend their aggressive accounting assumptions and rationalise the value of legacy silicon, hyperscalers rely heavily on a conceptual framework known as the ‘GPU Value Cascade’ or the ‘computing cascade’. The idea is that while a cutting-edge GPU may rapidly lose its utility for Tier 1 frontier model training within a mere two years, it can be seamlessly and economically redeployed to handle Tier 2 inference workloads for the remainder of its 5-6 year accounting life.
Because inference workloads are less computationally demanding and are projected by industry optimists to consume up to 80% of all AI compute cycles by 2030, the theory suggests these older, cascaded GPUs will always find a revenue-generating home.

The cascade theory seems at first like an elegant, capital-efficient lifecycle management strategy. Reality, however, paints a starkly different picture. The cascade model is actively collapsing under the weight of saturation, extreme power economics, and the rapid rise of custom silicon.
First, the sheer volume of GPU spend - with eight major companies expected to invest over $300 billion in AI infrastructure in a single year - guarantees a saturation of the secondary inference market. If millions of retired training GPUs cascade into the inference pool simultaneously, and enterprise inference demand fails to scale at the exact exponential, 16x rate required to absorb them, secondary rental prices will collapse entirely.
Current saturation modelling indicates that if inference workloads only achieve 8-10x growth, 40-50% of these cascaded legacy GPUs will have absolutely no workloads assigned to them. They will sit idle, generating zero revenue while continuing to occupy fiercely contested rack space and incurring baseline cooling costs.
Second, the hyperscalers are actively destroying their own safety net by aggressively designing custom ASICs explicitly optimised for inference. If a highly specialised, vertically integrated $10,000 inference ASIC - such as AWS Inferentia, Microsoft Maia, or Meta MTIA - vastly outperforms a power-hungry, repurposed $35,000 legacy training GPU on inference tasks, the older GPU becomes instantaneously obsolete for both training and inference. The cascade model breaks entirely, and the residual value of the legacy hardware evaporates.
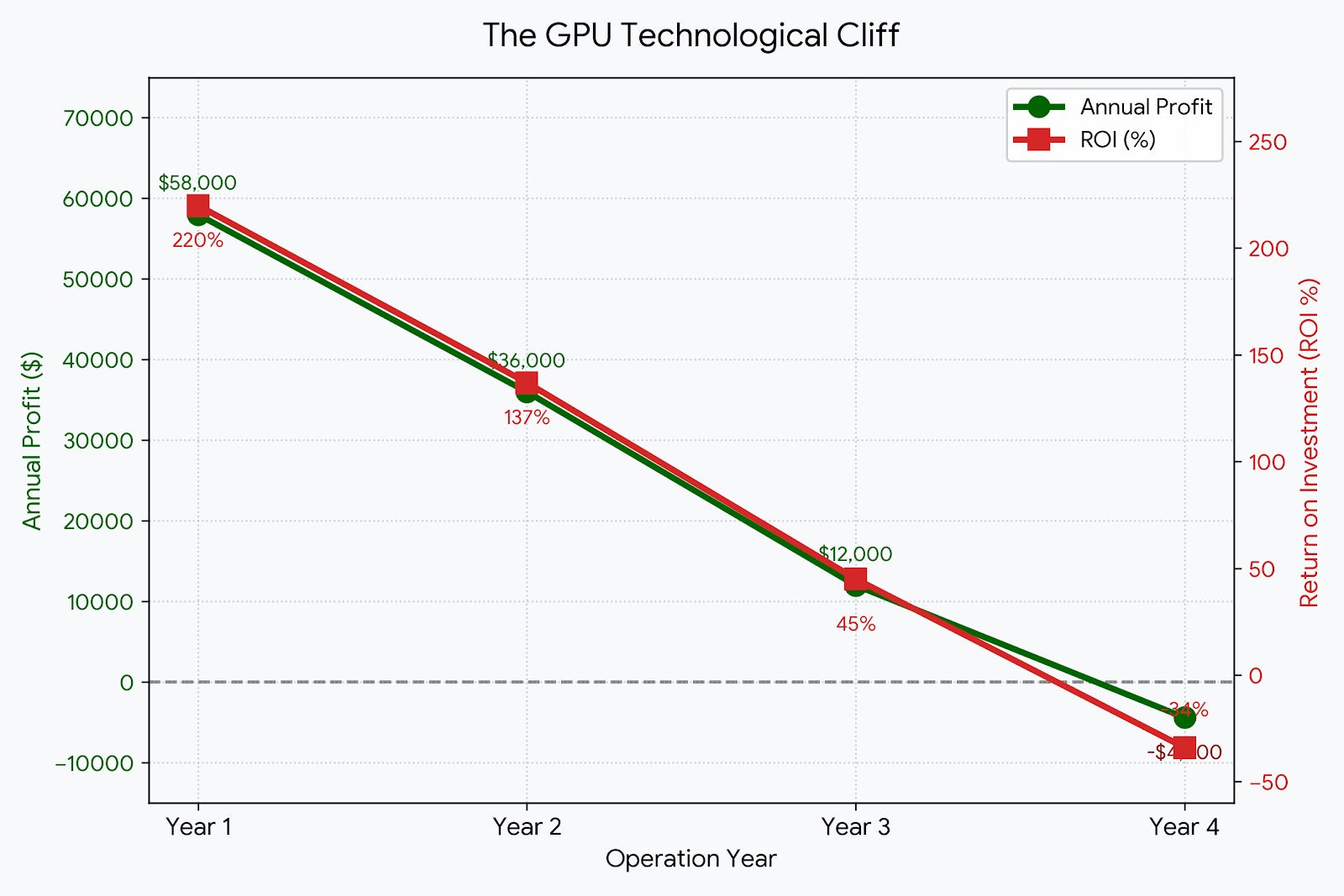
The financial degradation resulting from this technological cliff is already observable in the underlying economics of the hardware. Industry data detailing the profitability of Nvidia’s industry-standard H100 GPUs shows us a telling trajectory. In its 2nd year of operation, an H100 produced $36,000 in annual profit for a 137% ROI. However, that exact same unit is projected to lose over $4,400, resulting in a negative ROI of 34%, by year four. The economic life of the hardware is undeniably decoupling from its accounting life, leaving hyperscalers holding deeply unprofitable assets.
Linear Accounting and Depreciation
Accounting departments across the tech sector are using standard, linear accounting rules to forcefully smooth out the brutal, front-loaded income statement hit generated by this historic CapEx supercycle. This financial engineering creates a mirage of profitability that conceals the rapid destruction of shareholder capital.
CapEx first hits the cash flow statement, then boomerangs back over the subsequent years via depreciation to dent earnings. When companies artificially alter the speed of that boomerang, they distort the entire reality of their enterprise value.
Manipulating Useful Life
The way companies distort earnings is via the coordinated manipulation of the ‘useful life’ assumption applied to server and network equipment infrastructure. Over the past few years, the major hyperscalers have engaged in a systemic, lockstep elongation of their depreciation schedules.

Amazon extended its server depreciation from 3 years to 4 years in January 2020, and subsequently pushed it to a remarkable 6 years by early 2024. Microsoft extended its assumption from 4 years to 6 years for both server and network equipment within its cloud infrastructure. Google followed suit, moving to 6 year useful life assumptions alongside its peers. Meta has also pushed the boundary to 6 years.
Even private, highly speculative cloud GPU rental companies, such as CoreWeave, unilaterally extended their GPU depreciation periods from 4 years to 6 years to improve their financials ahead of debt syndications.
By stretching the depreciation schedule from a realistic 2-3 year window out to a uniform 6-years, these companies collectively saved an estimated $18 billion in annual depreciation expenses, directly and artificially inflating their reported operating income without altering a single operational reality.
Microsoft’s CEO explicitly highlighted the internal motivation for this capitalisation approach, stating a clear desire to avoid getting “stuck with 4-5 years of depreciation on one generation”. This is an outright admission that the technological lifecycle of the underlying silicon is far shorter than the accounting timeline they are presenting to investors. The economic usefulness is usually much shorter than the amortisation period, a dynamic that allows companies to systematically overstate the long-run sustainability of their profit margins by a factor of 2.
Furthermore, these accounting policies blatantly ignore the fundamental realities of component-based depreciation. Under GAAP, companies are explicitly permitted and encouraged to use component depreciation when specific components of an asset possess materially different useful lives.
The infrastructure of a modern AI factory - the heavy server chassis, the complex networking fabric, the massive power distribution units, and the liquid cooling systems - may legitimately possess a 6-8 year useful life. However, the frontier GPU modules housed within that infrastructure have a highly constrained, realistic useful life of just 3.5-4.5 years at maximum, with a realistic salvage value plunging to 30-35% almost immediately.
By applying a blended 6 year rate to the entire rack, management teams are severely understating the economic consumption of the silicon itself, artificially shielding their current earnings from the technological decay occurring inside their own data centres.
Highlighting this exact divergence, Amazon quietly reversed its policy in early 2025, shortening its server and networking equipment useful life back down to 5 years from 6, explicitly citing the “increased pace of technology development” in AI and machine learning.
To prioritise accounting integrity, Amazon was forced to accept an immediate $700 million operating income hit. Yet, the rest of the industry remains entirely committed to the 6 year fantasy.
Skeptics, including prominent investors like Michael Burry, argue that hyperscalers use these useful life extensions as an active, manipulative lever to inflate and smooth reported earnings even as underlying FCF collapses under the weight of continuous CapEx.
The Maths of Depreciation
The real devastation from this accounting mismatch comes only when one rigorously models the depreciation stack over a multi-year CapEx sprint. Because the hyperscalers are locked in a relentless, zero-sum arms race for frontier model dominance, they cannot only buy one generation of hardware and rest upon its amortisation schedule. They must continuously purchase the entire sequence of Nvidia’s accelerating product roadmap.
Consider the compounding effects of this for theoretical, standard hyperscaler caught in this treadmill.
If a hyperscaler spends $150 billion in Year 1 on Hopper architecture, those assets are placed on a 6 year depreciation schedule, generating a $25 billion annual headwind to the income statement.
In Year 2, to remain competitive for the next frontier model iteration, the hyperscaler must spend $190 billion on the vastly superior Blackwell architecture. The Year 2 income statement now absorbs the $25 billion from Year 1, plus a new $31.6 billion from Year 2.
In Year 3, the deployment scales to $220 billion for Rubin architecture to avoid ceding ground to rivals. The depreciation headwinds are now stacking aggressively and inescapably.
The trap springs completely shut precisely in Year 3 and Year 4.
By Year 4, the underlying Hopper architecture acquired in Year 1 has become completely unequipped to handle modern workloads. Its energy efficiency is atrocious compared to the Rubin Ultra standard, and its secondary rental market has evaporated due to ASIC saturation. Its true economic utility has effectively dropped to zero.
Yet, because of the six-year linear accounting fiction, that Year 1 hardware still carries over $75 billion in unamortised book value on the balance sheet, and continues to siphon $25 billion annually from the income statement for another two years.
The hyperscaler is thus forced to absorb the massive drag of operating completely obsolete equipment while simultaneously funding the acquisition of cutting-edge replacements. The capital destruction is compounding exponentially, eating away at the core profitability of the company.
Inevitable Asset Write-Downs
The endgame of all this is inevitable and entirely unavoidable: non-cash impairment charges, universally known as sudden asset write-downs.
When hyperscaler management teams finally concede that their legacy server clusters can no longer rent out compute space to enterprise customers at a premium - because enterprise demand has shifted entirely to the superior economics and faster processing times of next-generation architectures - they cannot simply continue carrying those dormant assets at their historical amortised cost.
Under GAAP rules, when the carrying value of a long-lived asset exceeds its undiscounted future cash flows, the company must immediately recognise an impairment loss, marking the asset down to its actual fair value.
The Cliff
The scale of the write-downs threatens to permanently shatter the net income margins of the tech sector’s darlings. Between 2023 and 2026, it is estimated that $1.5-$2.0 trillion in cumulative GPU-related CapEx will be placed onto balance sheets under these highly optimistic 5-6 year depreciation schedules.
If the real economic life of these assets reverts to the proven 2-3 year timeline due to frontier obsolescence, the cumulative overstatement of asset values currently living effectively as ghosts on big tech balance sheets exceeds $205 billion.
If this analysis is correct, which I believe it is, a brutal wave of non-cash impairment charges is imminent, waiting only for a catalyst to force someone’s hand. The potential cumulative individual write-down exposures are catastrophic for equity valuations historically predicated on margin preservation.
Microsoft faces potential write-downs ranging from $25-$50 billion.
Amazon carries an exposure of $20-$40 billion.
Alphabet risks a $20-$35 billion hit.
Meta faces a hit of $15-$30 billion.
Consider Microsoft as a primary example of this vulnerability. The equity market currently prices Microsoft on the assumption that it will maintain its historic, software-driven net income margins of 38%.
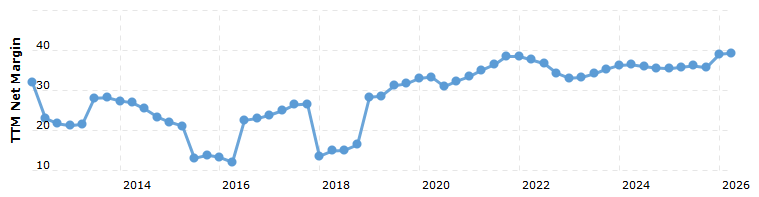
It is impossible to maintain a 38% net income margin when the company is forced to suddenly absorb a multi-billion dollar non-cash write-down on completely obsolete hardware, concurrently with surging debt service costs required to fund the next inevitable wave of hardware purchases
The income statement will be gutted by the ghosts of CapEx past, revealing a capital intensity profile that looks more like an offshore oil driller than a software monopoly.
The Neocloud Debt Bubble
This trap is further magnified when considering the highly leveraged peripheral players - the independent neoclouds and speculative research labs. These entities, unlike MSFT or GOOG, do not possess the diversified software revenues, global enterprise lock-in, or AAA balance sheets needed to weather a storm. They are pure-play compute arbitragers, and they are financing this rapidly decaying hardware through extremely aggressive, highly structured debt facilities.
CoreWeave exemplifies this sector-wide risk. The firm, which pivoted from crypto mining to AI infrastructure, has secured over $28 billion in debt and equity financing commitments over a 12-month period to expand its footprint.
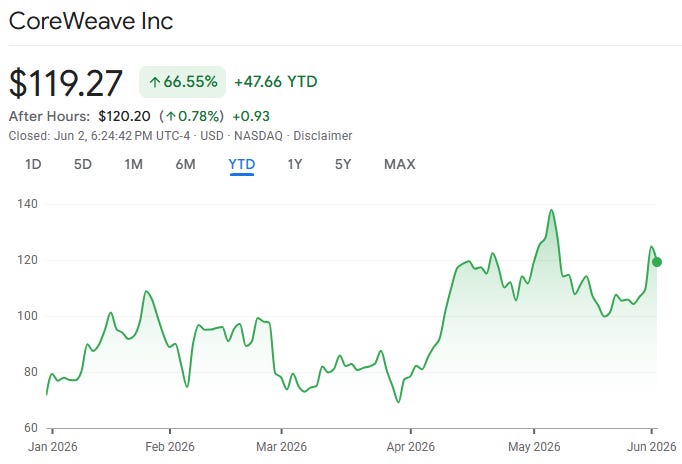
The premise of these massive debt structures is deeply flawed. These loans are secured by the high-performance computing infrastructure itself - the rapidly decaying GPUs - and the associated customer contracts linked to that specific hardware.
The financial alchemy here is astounding. The debt receives ‘investment-grade’ ratings not because CoreWeave possesses an investment-grade balance sheet, but because the customer on the other side of the compute contract, such as Meta, is creditworthy.
The credit market is mispricing the risk of the underlying silicon. These debt facilities feature maturities extending out to March 2032. By 2032, the H100 and Blackwell hardware serving as the physical collateral for these multi-billion dollar loans will be literal relics, possessing the relevance of a floppy disk.
When the underlying GPU hardware hits its obsolescence cliff in year 3 or 4, its residual value will collapse to near-zero. If the enterprise clients default, pivot their architectures, or simply refuse to renew expensive rental contracts on completely obsolete hardware, the lenders are left holding highly depreciated silicon that is fundamentally useless. This is subprime lending, secured by rapidly decaying semiconductor compute.
I published this article on CRWV late last year. Read if you’re interested in a full breakdown of the company.
Ambition Meets Reality
The Stargate Project - an aggressively promoted $500 billion joint venture involving OpenAI, SoftBank, Oracle, and the UAE investment firm MGX - was designed to build a nationwide network of 10GW AI data centres, positioning the US at the forefront of AI development. It was the ultimate manifestation of the CapEx supercycle.
However, the project is stalling, exposing the fault lines beneath the trillion-dollar buildout. Reports indicate that 14 months after its grand conception, the project has failed to raise the necessary funds to meet its initial budget, currently possesses no dedicated staff, and faces complete market uncertainty regarding AI hardware valuations.
The crisis culminated in the cancellation of a massive 600MW expansion at Stargate’s Abilene, Texas data centre campus - a project initially estimated at $15 billion and operated by Crusoe Energy Systems. The collapse of this specific expansion was reportedly driven by severe financing constraints and what was characterised as OpenAI’s “often-changing demand forecasting”.
That is the tell. OpenAI is experiencing genuine uncertainty about future compute needs driven by a shift from training-centric to inference-centric architectures. If the buyers of the compute cannot accurately predict what hardware architecture they will need in 36 months, securing 10-year debt financing against that specific hardware is a fool’s errand.
The hyperscalers and their ecosystem partners are beginning to choke on the sheer scale of their own capital destruction, discovering that the world of steel, copper, and thermodynamics does not bend to the timelines of software deployment.
Infrastructure Sellers
The irony of the GenAI boom is that the process threatening to destroy the hyperscale buyers and the neoclouds - rapid hardware obsolescence - is the most deeply bullish catalyst imaginable for the infrastructure sellers.
The broader market will look at the accelerating depreciation schedules, the $115 billion projected cash burns, and the collapsing data centre deals, and fear an industry-wide collapse. In reality, physical bottleneck monopolies will merely extract higher, inescapable tolls from the trapped participants.
Every single time a hyperscaler is forced to tear out a 2 year old GPU cluster to stay competitive in the frontier model arms race, they must immediately purchase entirely new silicon. This forced, rapid churn cements the pricing power of the upstream supply chain: the lithography providers, the leading-edge fabricators, and the grid equipment manufacturers.
The buyers are trapped on a treadmill. The sellers own the electricity powering it.
While the broader market stares in horror at $115 billion cash burns and fears an industry-wide big tech collapse, a very specific subset of infrastructure monopolies is extracting inescapable, high-margin tolls from this panic.
Below, I break down the bottleneck companies that are fundamentally immune to the GenAI depreciation cliff, and why their pricing power will compound as the hyperscaler trap springs shut.
